

Clinical Research
/
December 2025
About Hearing Loss

In the 1990s, the hearing aid industry underwent its last great revolution: a shift from analog to digital. It was a miracle of miniaturization that promised a future where people with hearing loss could hear clearly once again.
But for the next thirty years, that promise went largely unfulfilled.
While the chips inside our smartphones were doubling in processing power every eighteen months, the ones inside hearing aids remained stuck in an era of incrementalism.
This created a ceiling for the most difficult challenge associated with hearing loss: the ability to pick one voice out of a noisy room. To finally solve this challenge, we had to throw away the conventional hearing aid architecture altogether.
For decades, hearing aids relied on Digital Signal Processing (DSP). These hearing aids analyze sound based strictly on its physical properties like frequency, pitch, and amplitude.
The first digital hearing aids worked like crude volume knobs, turning down anything too loud or too high-pitched. But background noise and speech often live in the same frequency range, so turning up speech meant blasting the wearer with all the noise around them too.
Engineers then created denoising algorithms that tried to identify speech by detecting statistical patterns in sound, but still relied on the physical properties of sound. They could spot sounds that looked like speech (rhythmic pulsing, pauses) and amplify those over steadier sounds, like the hum of highway traffic.
But this fell apart the moment a wearer walked into a restaurant. Laughter, clinking glasses, and overlapping conversation look a lot like speech too, so the system couldn't tell the difference between your spouse's voice and the chatter around you.
When AI arrived, most manufacturers used it to paper over this problem. The AI would listen, label the environment—"restaurant," "outdoors," "concert"—and switch between pre-programmed filter settings. It was basically an automatic knob-turner.
Through thirty years, the underlying architecture of hearing aids never changed. To truly separate a single voice from the noise, AI couldn't just sit on top of the sound processing system. AI had to become the system.
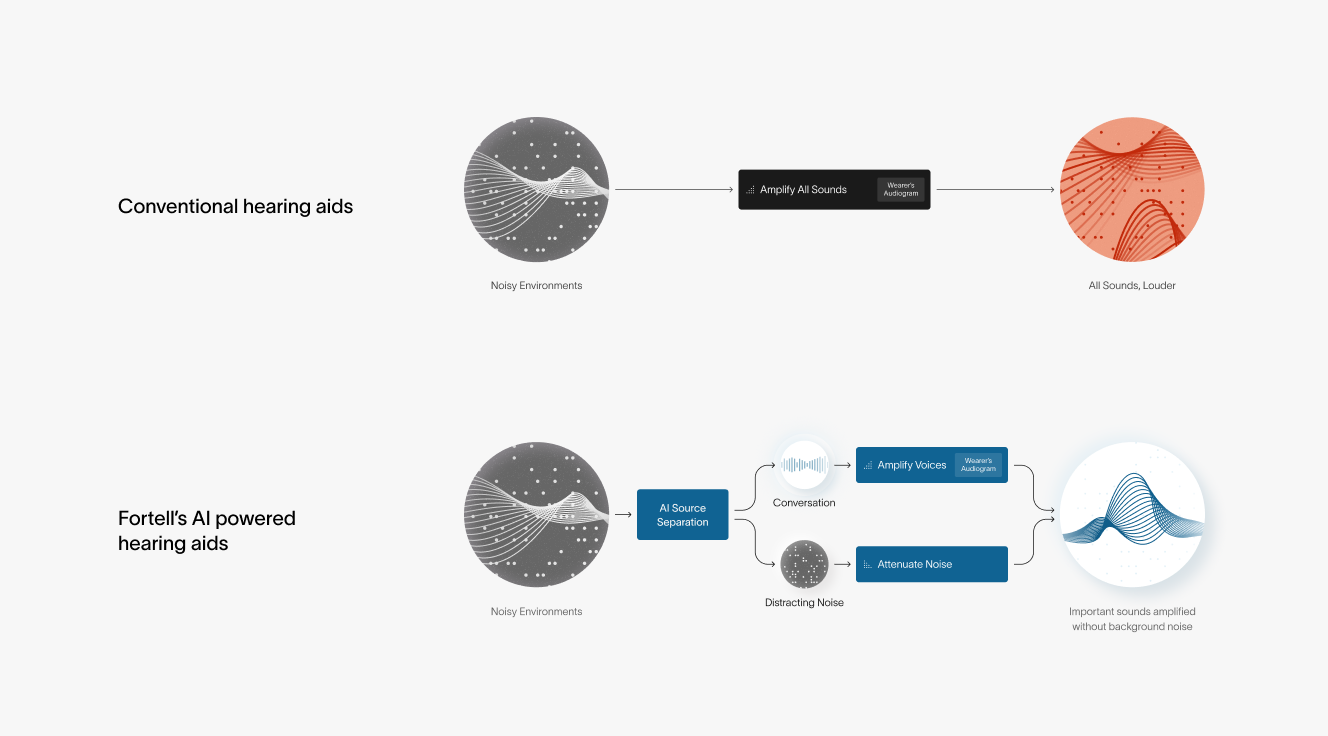
Using AI at the sound processing layer changes what’s possible. Instead of using fixed rules (conventional sound processing) to determine what to amplify and what to suppress, we can train the AI with millions of nuanced examples so it can identify speech vs. noise even in tricky scenarios. For example, in a crowded room, we can train the AI to pick up on a target voice and suppress background voices even though they both look like speech.
In effect, AI processing functions more like the human brain than conventional sound processing. In healthy hearing, our brains naturally filter out the clatter of plates and other nearby conversations to focus on the person in front of us. Conventional processing lacks the ability to distinguish other noise from the voice we want to hear, and often amplifies everything, making loud places even louder. AI processing mimics the brain's ability to recognize patterns and isolate a speaker’s voice from the surrounding noise. This allows a wearer to follow a conversation with much less effort.
Teaching our AI to achieve this pattern recognition required a massive, multi-stage effort. We built our own dedicated training clusters using NVIDIA GPUs, the same infrastructure used to power the world’s most advanced AI models.
Phase 1: We trained the model on millions of clean audio samples to teach it the basic DNA of human speech.
Phase 2: We introduced hundreds of hours of raw recordings of "dirty" audio (horns, clicks, clanks, and chatter) to teach the model how to separate target voices from noise.
Phase 3: We incorporated audio recorded directly from hearing aid microphones to ensure the model could process the specific distortions and limitations of the tiny hardware.
After this multi-year training effort, we finally had an AI model that worked seamlessly… on a laptop. The real challenge now was to miniaturize that intelligence.
A laptop draws around 50 watts of power. A hearing aid runs on roughly one milliwatt — 50,000 times less. The model that worked beautifully on a laptop now had to fit inside something smaller than a fingernail, run on a fraction of the power, and process every sound in under a hundredth of a second.
We looked at every chip on the market. None of them could do this.
Standard chips are "Jacks of all trades," designed to handle everything from Bluetooth connectivity to visual graphics. Because they aren't optimized for one specific task, they either pulled too much power or didn't have the compute to run our model.
We couldn't just buy a chip; we had to build one.
We needed an ASIC (Application-Specific Integrated Circuit) designed for exactly one thing: audio processing. By stripping away everything that didn't serve the ear, we could co-design the algorithm and the silicon together.
In the world of advanced silicon, TSMC is the only game in town for the small, power-efficient nodes we needed. But for a small company like us, this was a massive hurdle. Access to their advanced production lines is highly competitive and incredibly expensive.
We leveraged personal relationships with TSMC and people who know TSMC well to get our foot in the door. We weren't just asking them to make a chip; we were asking them to trust that our architecture was worth their capacity. Ultimately, they agreed.
A single "tape-out"—the moment you send your design to be turned into physical silicon—costs millions of dollars and the process can take close to a year. If there is a single logical error in the design, you don't just lose the money; you lose that entire year.
We felt confident taking this multi-million dollar swing because our founding team had spent their careers at the intersection of extreme compute and miniaturization.
Our co-founder and ASIC architect, Andy Casper, brought deep experience in specialized silicon from his time at Google. The team had also previously overcome similar miniaturization challenges at Butterfly Network, where they shrunk a room-sized ultrasound machine into a handheld device. They knew that a "bad chip" could take 12 months to fix, and they designed with the past learnings to ensure it worked the first time.

The day the physical chips arrived from Taiwan was one of the biggest moments in our company’s history. It can often take two or three tries to get a chip right, so the stakes were absolute. If the chip failed, it would be a bad year and a major setback.
We plugged the first chip into the test rig and watched as the built-in test programs ran their cycles. Then, the screen printed a single word: PASS.
The chip was logically correct, it hit our power numbers, and the audio matched the high-fidelity experience of the laptop. We had successfully packed hundreds of times more compute than a conventional hearing aid into a tiny piece of silicon.
Since the beginning, we didn't want to build a hearing aid unless it would be radically better than what existed. Our proprietary chip moves hearing technology out of the era of incremental improvements and into the intelligence era of hearing.
For decades, the industry has relied on a model of amplification and legacy signal processing. By rebuilding the system from the ground up, we have fundamentally changed what a hearing aid can do.

